Why Backend Developers Should Fall in Love with GraphQL too

 Anant Jhingran
Anant JhingranFor frontend developers, GraphQL represents a step function. First, it is an intuitive query language for backend data, providing a single endpoint for developers when making requests. Second, GraphQL brings efficiencies since it prevents multiple backend calls. Additionally, excellent open source tools and self-documentation improve the developer experience — no more reading of clunky OpenAPI docs.
It’s no surprise then that industry rags and developer adoption surveys predict more than a million developers will use GraphQL in some shape or form over the next three years.
But if you, as a backend developer, are looking at it and saying, “this is another fad and another nightmare for me,” let me take the next few minutes to tell you why it is an excellent technology for you too.
Backend Teams Have Concerns
Let’s set the context. In our conversations with developers, we’ve heard the following concerns:
First, neither my team nor I have the skills to build out GraphQL APIs. GraphQL represents a new compromise vector. We locked down SQL injection, then REST, and now I have to worry about something else? Current tools in GraphQL make mixing business logic and declarative logic very easy, and that is an anti-pattern. And the most important one: I have years of investment in building out REST endpoints, so do I need to throw that away and start from scratch? These concerns are valid, but as is often the case with any new technology, the reality is not as bad as it might seem. Plus, serving GraphQL is a dynamic software development landscape, with open source tools like GraphQL Mesh and vendors like Apollo, Hasura and StepZen (where I work) beginning to address these concerns.
But while allaying concerns is essential, it is more important to consider whether GraphQL is a good, or even robust, technology for a backend developer to build APIs. Or is it just something that she is being asked to provide by the frontend teams? I argue the answer is a resounding yes to GraphQL as an excellent technology for backend teams.
Backend Teams have to Wrangle Various Backend Data Sources
The core problem that backend developers have is that they have backends! And not one, not two, but dozens or even hundreds. The fissiparous tendency of data exceeds any unifying force! Therefore the problem becomes one where you have to produce a consistent GraphQL API, even though the backends are all different.
More than that, the data must be mixed and matched.
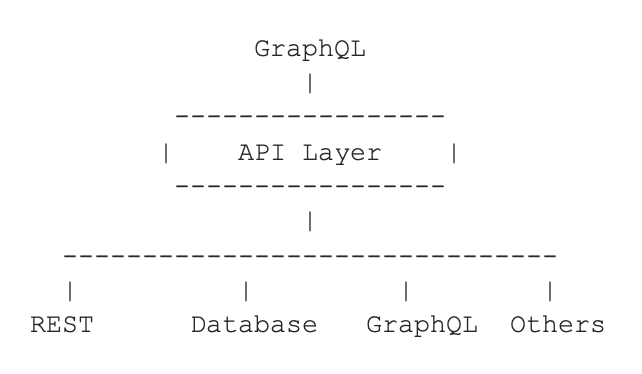
So the API layer that you build needs to have the following characteristics:
- Ability to mix and match JSON from REST or GraphQL, tabular results from SQL databases and XML from the older generation of backends.
- Ability to connect the dots: Given X, find Y. For example, given a “customer’s email,” return “the delivery status of the customer’s orders.”
- Abstraction for the most common use cases. For example, “a customer is a customer irrespective of the backend that provides the data,” and get details about the customer when necessary — for example, “paying customers have associated credit card information, so retrieve that information too.”
- Auto-generated documentation and introspection capabilities.
Let’s elaborate on each of these.
Mixing and Matching Responses
JSON, or some hierarchical representation, seems to be the suitable representation internally in the API layer, because it is a superset of the most common responses from the backend. (We can easily convert XML to JSON.) But it turns out that connecting different responses benefits enormously from GraphQL constructs.
As an example, suppose you want to provide the ability to “add weather to the delivery status using address+date to call weather.” The ability to “query” the weather backend using extracted values from the delivery backend is required. So what you want is:
type Delivery {
address: String
status: String
deliveryDate: Date
...
}
extend type Delivery {
weather: Weather #using query weather(address:String!, date: Date!)
}
type Query {
deliveryStatus (trackingId: String!): Delivery
weather (address:String!, date: Date!): Weather
}
In effect, you are stitching the two types — Delivery and Weather — using GraphQL query capabilities. First, we use the extend clause to specify that a new field, weather, should be added to type Delivery. This stitching allows for a separation of concerns. You may see this “stitching” capability referred to as “federation.”
Second, and more importantly, you are best off making the connections using GraphQL’s query capabilities. So, in this case, connect Weather into Delivery by calling a GraphQL query (weather) and passing it the correct parameters.
There might be other ways to build your mix-and-match middleware, but using GraphQL constructs is perhaps the easiest and the cleanest way.
Ability to Connect the Dots
GraphQL has a fantastic way for the frontend developer to connect the dots. Let’s take an example in which a developer is building an eCommerce site. She might be making a page where the user’s identity is known, but she also wants to get the delivery status of that user’s orders. So she might build in a query that looks like the following:
{
deliveryStatus (email: String!) {
status
deliveryDate
}
She does not know and does not care that for this query to be supported, someone has to connect the dots between Customer, Order, Lineitem, Shipment, and Delivery.
So behind the scenes, the above query may need to get translated into something like this:
{
deliveryStatus (email: String!) {
customerInfo {
orderInfo {
lineitemInfo {
shipmentInfo {
deliveryInfo
}
}
}
}
}
}
In other words, supporting intuitive queries for developers to use is about building some other queries that abstract other GraphQL queries. Furthermore, if your internal middleware has the concept of GraphQL built into it, it will be straightforward.
Abstraction and Details Come Together
You have two backends, one managing customers on a free plan and the other managing customers on a paid plan. While the two may have a lot in common, they will also likely have many different capabilities.
In a simple example, the backend that deals with the customers on the free plan might have an expiry date, and the backend that deals with customers on a paid plan might have a creditCard associated with the customers. Designing a Customer interface that is the union of the two is a nightmare, and most of the time, records will result in lots of NULL. But, on the other hand, designing to the lowest common denominator also does not seem right, because the differences between the two systems get lost.
GraphQL has a great mechanism using fragments, where a developer might issue a query like this:
{
customer(email: "john.doe@example.com") {
name
address
... on Free {
expiry
}
}
}
Fragments allow the developer to deal with the abstractions when needed (name, address), but dive into details when necessary (expiry). As a backend developer, this is awesome. You have an API that is not reduced to the lowest common denominator. Or perhaps better said, you have an API where you have complete control over what abstractions, and what details, you expose. As more backends come online or as requirements change, developers can adjust the boundary between abstractions and details.
Auto-generation of Documents and Introspection Capabilities
OpenAPI is awesome. It leads to good docs from various companies like SmartBear, Redoc and others. Postman can help generate docs too. However, GraphQL takes documentation to the next level. I have not read a GraphQL API doc in a long time. Not that they do not exist. But honestly, they are not needed. There are two reasons for this:
- GraphQL supports introspection. So there are tools — and there are plenty out there — that can introspect a backend and determine the capabilities it exposes. I love GraphQL a lot, but this is one feature that is mind-blowing for me. So many REST-based APIs come with docs generated from an OpenAPI spec, a Postman collection or whatever. Still, they are all designed to be then interacted with by a developer, and the introspection capability is lost.
- Yes, interacting with a REST API through its interactive docs is fun and helpful. But the free availability of tools like Insomnia, GraphiQL and GraphQL Playground make the interactivity for GraphQL endpoints so much more intuitive for the developer.
As the backend person, the API provider, you do not want just to build out APIs, you want to build out APIs that are intuitive and easy to explore, test drive and learn. GraphQL introspection, along with open source tools, takes this to the next level. You no longer spend time correcting mistakes in docs or keeping up with documentation as your API changes. Instead, GraphQL APIs automatically show up to be test-driven, comments and all.
Summary
As someone responsible for building out the APIs that someone else (or even you!) uses, it is simply better done with GraphQL. GraphQL helps you deliver more intuitive APIs to your users. Stitching functionality together helps you effectively mix and match responses from backends. GraphQL fragments help with the abstraction and details continuum, and introspection along with self-documentation capabilities save you time.
I have done SQL for over two decades at IBM. I have done REST APIs for almost a decade at Apigee and Google. So I firmly believe that GraphQL, for all its weirdness, gets it right, not just for the frontend developer but for the people whose jobs are to corral and carefully expose backends.
As you would guess, we at StepZen are building these observations into our software. Give it a try. It’s free to sign up at stepzen.com.
Originally published in The New Stack