What I Learned from Reading the GraphQL Spec - Part 1

 Leonardo Losoviz
Leonardo LosovizI've been working with GraphQL for several years and have read the GraphQL spec a few times. There are many things that have called my attention, particularly those details which may not appear important at first, but may have a deep impact in how servers implement GraphQL, and users interact with it.
Then, a few weeks ago GraphCDN published blog post What I learned from reading the GraphQL Spec, pointing out several things that called their attention. I thought it was a good read, so I'd like to complement that article, writing about those details from the spec that I find particularly interesting. This article is the result.
The information I've gathered from the spec includes what is described there and, as importantly, what is not (but we could reasonably expect). In addition to the spec, I've retrieved facts from GraphQL's GitHub repo, where we can appreciate what features are currently missing in GraphQL and which ones will eventually be supported.
As I gathered so many noteworthy details, I've written this article in 2 parts. This is the first part.
Graphs are not really part of the spec
This one may sound anti-intuitive, but the "graph" in "GraphQL" is just a model for dealing with the data, and not an actual imposition by the spec. Searching by the whole word "graph" in the spec produces only 2 results, and neither of them is related to the data model:
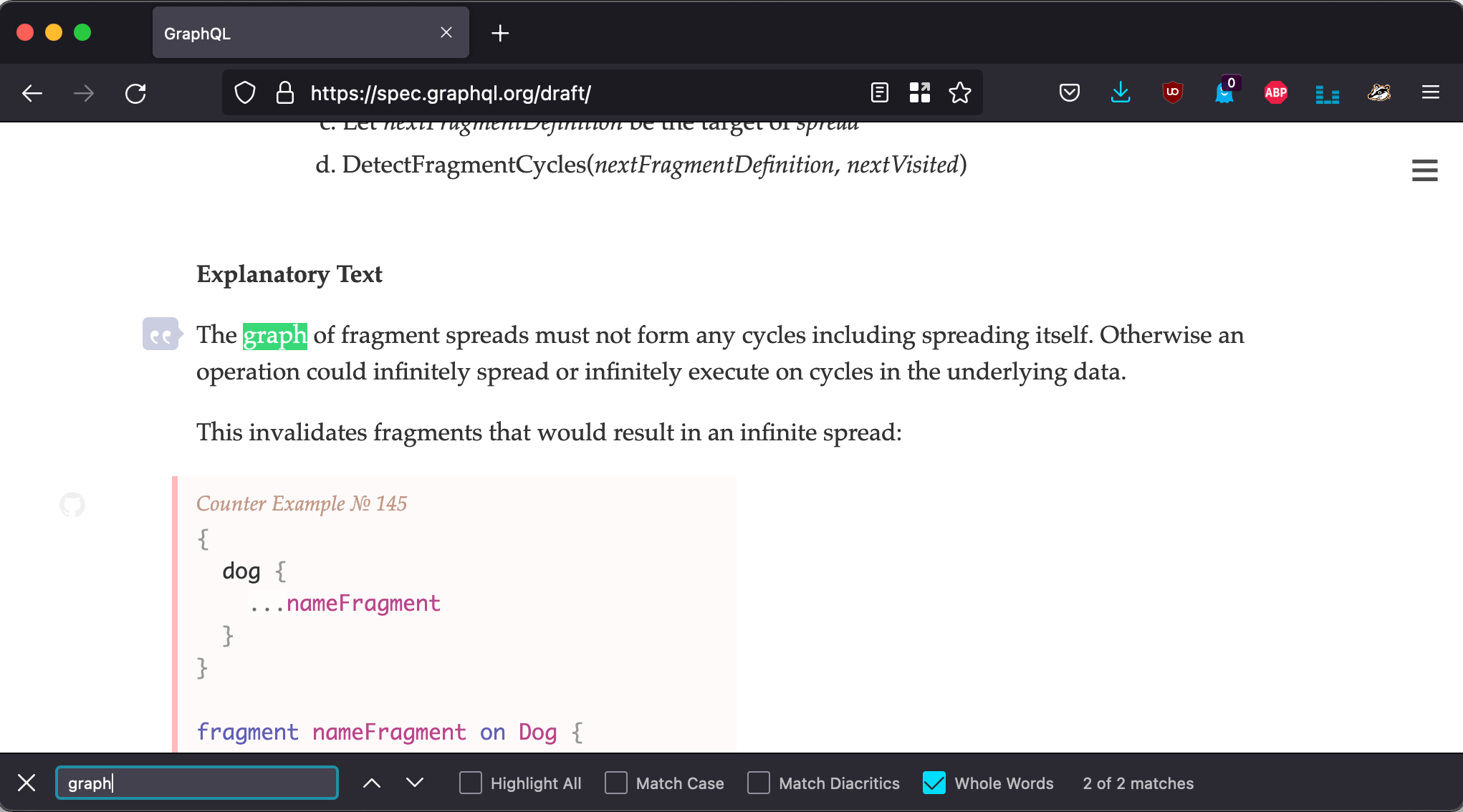
The graph model is useful because it allows to represent queried entities as nodes, and their relationships to other entities as edges. As section "Thinking in graphs" from graphql.org says:
With GraphQL, you model your business domain as a graph
Notice the word "model" there: GraphQL servers can use a graph in the algorithm that resolves the queries, but they don't have to. Indeed, GraphQL servers can internally represent data using any model they choose, such as with components, if it brings performance or other gains.
This decoupling from concept to implementation means that GraphQL can work with any source of data, and not only with graph-based databases (such as Neo4j), as developers might wrongly believe.
Recursions are forbidden (but there is a proposal to support them)
Validation item 5.5.2.2: Fragment spreads must not form cycles forbids fragments from being recursive, hence a fragment is not allowed to reference iself, whether directly:
query {
users {
...UserProps
}
}
fragment UserProps on User {
...UserProps
}
Or transitively:
query {
users {
...UserProps
}
}
fragment UserProps on User {
...MoreUserProps
}
fragment MoreUserProps on User {
...UserProps
}
GraphQL creator Lee Byron explained why recursions must not be allowed:
The issue is that GraphQL has no way of actually confirming that the data it encounters is not infinitely recursive. Without an ability to make this guarantee, allowing for cyclic queries could in fact expose infinite execution queries which could be used as an attack vector.
However, not everyone agrees with banning recursions: the recently-added issue #929 attempts to remove this restriction. The main argument to support recursions is that GraphQL connects to some data source, coded in some language, which will most likely accept recursions, so then why should GraphQL forbid them? Why is GraphQL restricting what we are already able to do at the origin?
For instance, take this recursive PHP code:
function filterFieldArgsWithEmptyValues(array $fieldArgs): array
{
return array_filter(
$fieldArgs,
function (mixed $elem): bool {
if (is_array($elem)) {
$filteredElems = $this->filterFieldArgsWithEmptyValues($elem);
return count($elem) === count($filteredElems);
}
return !empty($elem);
}
);
}
In it, the recursion will eventually come to an end, which is when the array has no more items. If careless, the developer may produce bugs and have the algorithm loop forever, but PHP does not prevent it in advance. That's a task for the developer to figure out.
The same situation could perfectly apply to GraphQL: if the developer knows that the query will eventually come to a halt, why should this be forbidden?
An example of a query that could be coded using recursions, because we know that it will not loop forever, is the introspection query used by GraphiQL and other clients to retrieve the complete schema for the GraphQL API. As it stands currently, this query must explicitly retrieve the maximum depth of type relationships in the schema, which is 7 levels deep:
fragment TypeRef on __Type {
kind
name
ofType {
kind
name
ofType {
kind
name
ofType {
kind
name
ofType {
kind
name
ofType {
kind
name
ofType {
kind
name
ofType {
kind
name
}
}
}
}
}
}
}
}
If recursions were supported, this query could be simplified and made more elegant:
fragment TypeRef on __Type {
kind
name
ofType {
...TypeRef
}
}
In my opinion, recursions should be allowed in GraphQL (I'd use them to simplify the queries to fetch navigation menus and nested comments). I'll keep watching issue #929 to see if it gains approval from the working group, and manages to get this feature approved for the spec.
Query-type directives are in limbo
This is not an item of what is documented in the GraphQL spec, but rather the contrary: there is not enough information on what the scope of a directive must be.
As the section on custom directives states:
GraphQL services and client tooling may provide any additional custom directive beyond those defined in this document. Directives are the preferred way to extend GraphQL with custom or experimental behavior.
What is custom or experimental behavior? It sounds like the wild west, where a directive can do anything it wants, as long as it doesn't produce some behavior that conflicts with the spec somewhere else (such as modifying the shape of the response).
This freedom is done on purpose: by not restricting directives, GraphQL servers can use them to support any custom feature (i.e. some feature not described in the spec). These features, if they prove useful, may eventually land in the spec (as a built-in directive or otherwise), thus improving GraphQL.
However, this freedom produces the negative effect that GraphQL servers, clients and tools may support directives in ways that are incompatible with each other. To be more specific, this happens with query-type directives, which are those added to the GraphQL query ( schema-type directives, in constrast, are under full control of the GraphQL server). This situation has even prompted some tools to discourage using query-type directives, even while supporting them!
In other words, query-type directives are in limbo, and it's not clear if we should we use them or not.
Directives may soon modify other directives
The section on directive locations indicates where it is possible to add directives:
ExecutableDirectiveLocation: one of
QUERYMUTATIONSUBSCRIPTIONFIELDFRAGMENT_DEFINITIONFRAGMENT_SPREADINLINE_FRAGMENTVARIABLE_DEFINITION
TypeSystemDirectiveLocation: one of
SCHEMASCALAROBJECTFIELD_DEFINITIONARGUMENT_DEFINITIONINTERFACEUNIONENUMENUM_VALUEINPUT_OBJECTINPUT_FIELD_DEFINITION
There are 2 items currently missing from these lists:
DIRECTIVEDIRECTIVE_DEFINITION
That is, it is currently not possible to apply a directive on another directive, whether when executing the query, or when defining the directive in the SDL.
But this situation may change soon: PR #907 aims to support directives being applied on directives. Its motivator is that we should be able to apply built-in directives @deprecate and @specifiedBy on directives too:
directive @upperCase
on FIELD
@deprecated(reason: "Use @uc instead")
directive @sequence
on QUERY | MUTATION
@specifiedBy(url: "https://...")
As I've recently shared in article GraphQL: On Directives Transforming the Behavior of Directives, if approved, this PR could unlock powerful new capabilities. For instance, it could allow any directive that receives an input of type String to also handle an input of type [String], by preceding it with a @forEach directive:
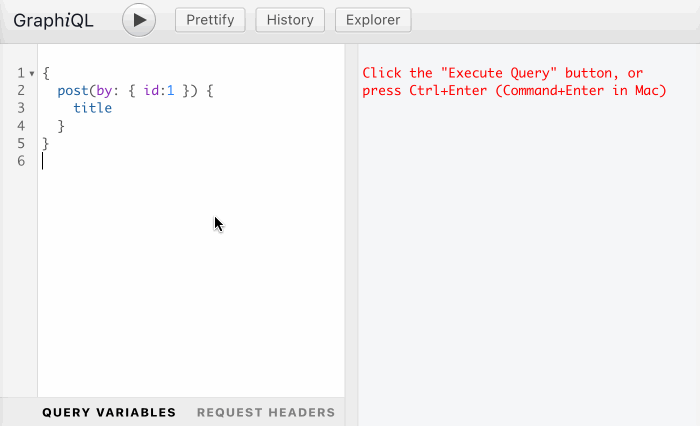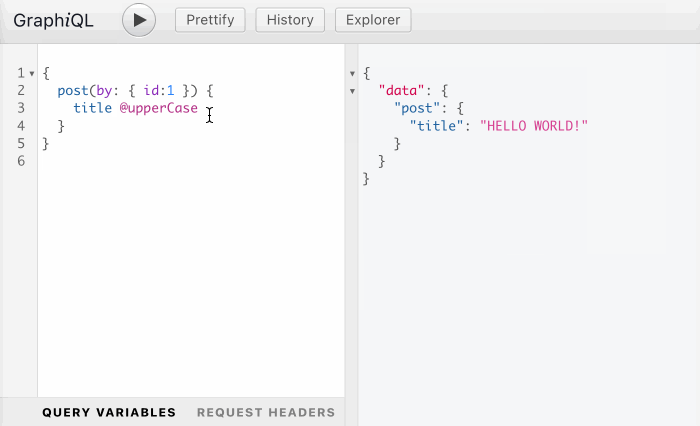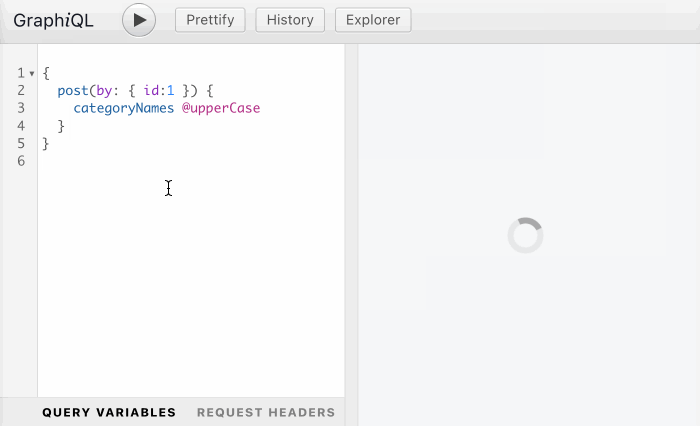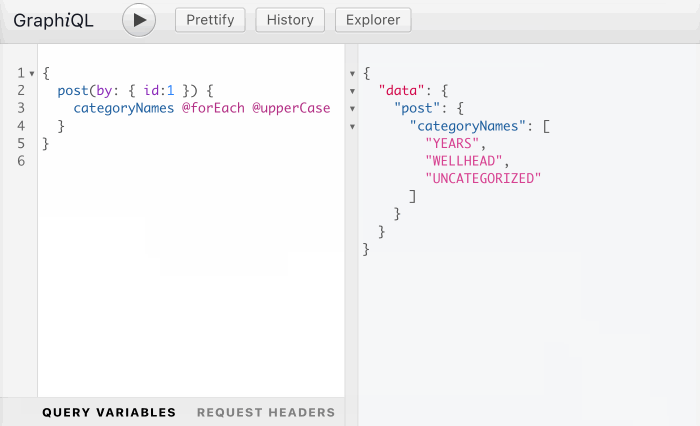
While the previous section explained that query-type directives are in limbo, this section expresses awe at the potential power of directives. That's why, in my opinion, we should not cut their wings, or we'll be making our APIs less powerful than they can possibly be.
There is no mention of the single endpoint
One of the biggest differences between GraphQL and REST is that REST exposes multiple endpoints, where each endpoint retrieves the data for a specific resource or set of resources, whereas GraphQL offers a single endpoint, and we must indicate what data to retrieve by executing a query against it.
However, when searching for "single endpoint" in the spec, there are no matches, and when searching for "endpoint" there is only one match, which bears no relationship to GraphQL's single endpoint:
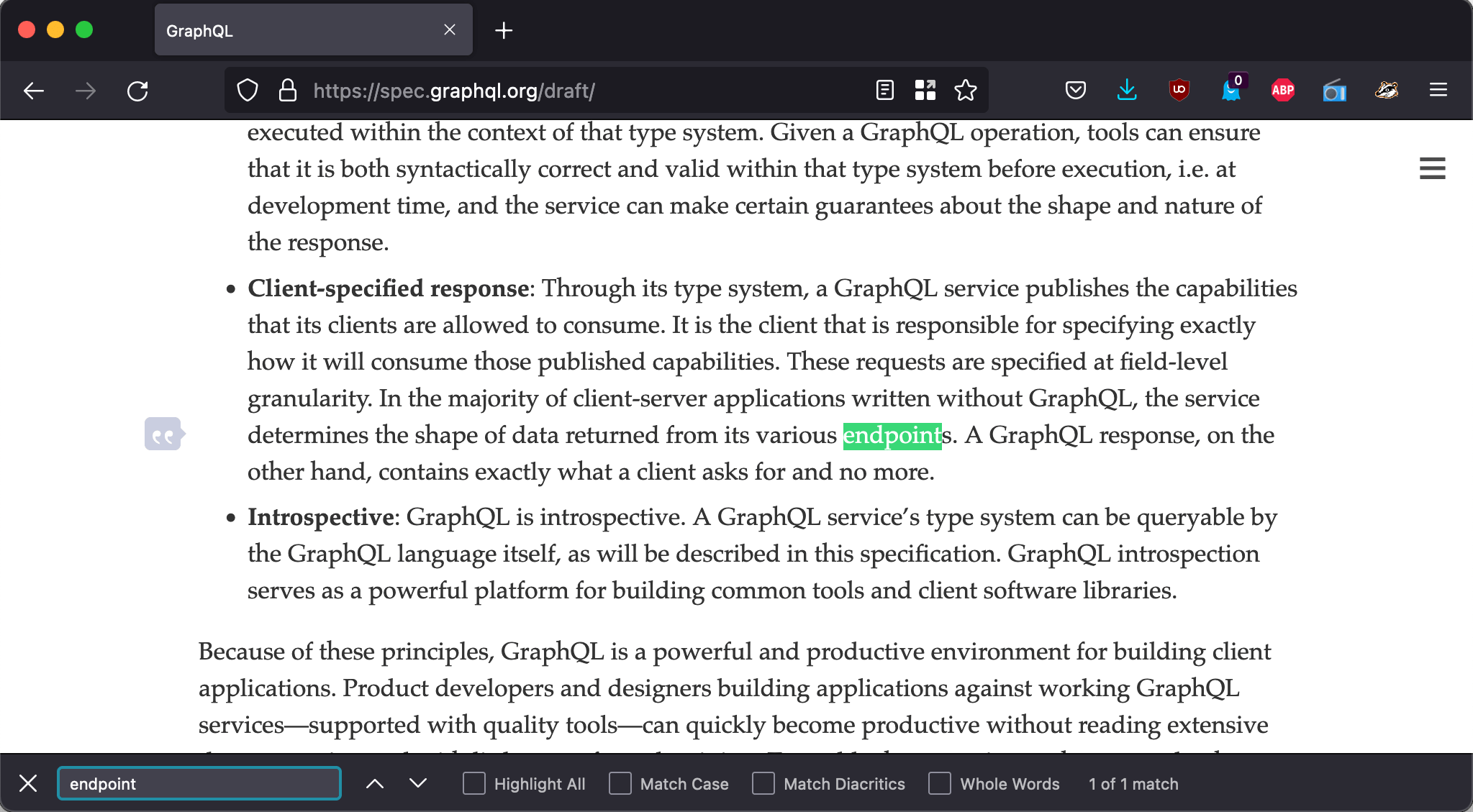
The single endpoint is a proposition, not an instruction. It is sufficient to expose a single endpoint in the GraphQL API to satisfy any query, but we can add more endpoints, if we wish to.
Why would we want to expose more than one endpoint? There are multiple use cases for it, such as:
- exposing the public and admin endpoints separately, under
/graphql/and/graphql/admin - restricting access to private information in a safer way, validating that only some specific IP can access some specific endpoint
- providing a different behavior to different applications, such as
/graphql/mobile/and/graphql/website/ - generating a site in different languages, such as
/graphql/en/and/graphql/fr/ - testing an upgraded schema before releasing for production, such as
/graphql/upcoming/and/graphql/nightly/ - supporting the Backend for Frontend (BfF) approach, to have different clients access (and control) their own endpoints
Since the spec will not say anything about the single endpoint, we need to read other resources to learn about it. For instance, the best practices on graphql.org has a section about it:
GraphQL is typically served over HTTP via a single endpoint which expresses the full set of capabilities of the service. This is in contrast to REST APIs which expose a suite of URLs each of which expose a single resource. While GraphQL could be used alongside a suite of resource URLs, this can make it harder to use with tools like GraphiQL.
Nested mutations are normally not allowed (but the server can decide)
In GraphQL we retrieve data by nesting fields in the query. For instance, retrieving the comments from a post is done like this:
query {
post(id: 1) {
comments {
id
date
content
}
}
}
What about mutating data by nesting fields, is that allowed? For instance, can we do this?
mutation {
post(id: 1) {
addComment({
content: "I agree with your example"
}) {
id
date
content
}
}
}
The answer is generally "no", because the GraphQL spec demands mutations to be placed only at the root, so we must execute this mutation instead:
mutation {
addCommentToPost({
postID: 1,
content: "I agree with your example"
}) {
id
date
content
}
}
The restriction is defined in the Mutation section, which states:
If the operation is a mutation, the result of the operation is the result of executing the operation’s top level selection set on the mutation root object type. This selection set should be executed serially.
It is expected that the top level fields in a mutation operation perform side-effects on the underlying data system. Serial execution of the provided mutations ensures against race conditions during these side-effects.
Because a mutation produces side-effects, the order in which different mutations are executed matters. For instance, altering the order of the mutations below will produce different results:
mutation {
appendContentToPost({
postID: 1,
content: " - Copyright 2022"
}) {
content
}
appendContentToPost({
postID: 1,
content: " - Written by: Leo"
}) {
content
}
}
That's why mutations must be executed serially. In order to enforce this, the fields in the root object are executed serially, and the mutations must be confined there.
Retrieving data, though, does not produce side-effects, so querying is allowed to be executed in parallel. Section Normal and Serial Execution explains:
Normally the executor can execute the entries in a grouped field set in whatever order it chooses (normally in parallel). Because the resolution of fields other than top-level mutation fields must always be side effect-free and idempotent, the execution order must not affect the result, and hence the service has the freedom to execute the field entries in whatever order it deems optimal.
The spec is then dividing field resolution into two parts:
- Fields in the root object must be executed serially, and they must include all mutations
- Fields in other objects can be executed in parallel, and in that case, they can include only queries
Now, while the first item is mandatory, the second one is a recommendation. Hence, GraphQL servers can decide to resolve all fields serially (not only those at the root object level), which would guarantee that nested mutations are always executed in the expected order, making them idempotent:
mutation {
post(id: 1) {
# This mutation will always be executed first
appendContent({
content: " - Copyright 2022"
}) {
content
}
# This mutation will always be executed second
appendContent({
content: " - Written by: Leo"
}) {
content
}
}
}
By doing so, GraphQL servers are able to support nested mutations. The decision is theirs.
Conclusion
The GraphQL spec is not difficult to read, and it provides invaluable information to help us understand how GraphQL works. Complemented with the issues and PRs in the GitHub repo, we can obtain a thorough understanding of the direction that GraphQL is heading, including what features are missing, and what features it is expected to eventually support. By reading these, we are able to gain useful insights to make the most of our GraphQL APIs.
I thoroughly recommend reading these resources, and not just once, but on a continuous basis to keep the insights coming.
Editor’s note: Our thanks to Leo for his guest post and perspective on the evolution of the GraphQL spec.
Check out the StepZen Getting Started wizard and our docs for information on how to get started quickly and scale your GraphQL implementation effortlessly. We hope to see you over on the Discord Community!


