GraphQL Makes Data Liquid — What It Means for Data Protection

 Anant Jhingran
Anant JhingranHaving done different forms of API infrastructure for over a decade, I can safely say that there is nothing as powerful from a data consumption perspective as GraphQL. A query like:
query MyQuery {
customerByEmail(email: "john.doe@example.com") {
city
name
orders {
createdOn
delivery {
status
}
}
}
}
makes the right customer, order and delivery data available to the API consumer, completely abstracting away the backend protocols, keys, locations and stitching requirements. It makes enterprise data “liquid” from a consumption perspective.
Liquid Data
But with such liquidity comes a danger. Let me draw upon my Apigee experience, where I saw this constant struggle in organizations. On the one hand, APIs were great — they reduced friction in the adoption of services and increased the topline. But on the other hand, they opened up a new channel of vulnerability. Could organizations eat the cake and have it too?
I used to give an analogy: You have a door or two to your house. You cannot have a house without a door. And you do your best to protect that door. You lock it so that only authorized people with keys can get in. You put security cameras to see if some unauthorized entry is happening, and so on. You balance a need (having a door) with a concern (security).
GraphQL poses similar challenges. On the one hand, it makes enterprise data easily available through a very flexible API. But on the other hand, given how easy it makes the data flow, we must ask what security challenges it creates that need to be addressed. If the two sides go hand in hand, then GraphQL will deliver on the promise of being the universal API standard.
In this article, we discuss three of these challenges and describe some of the mechanisms that can mitigate those challenges.
Data Rights
Is the query allowed to access the data it is asking for? There are three obvious places to check this:
- At the query structural level before it is even executed (“Whoa, why is the query asking for the details of john.doe@example.com when the credentials it has presented do not give it the permission?”)
- In the backend (“Sorry buddy, you are asking for order status from me, a database, but given the context I have, I cannot do that for you.”)
- In the GraphQL layer (“Hmmm, why are you asking for orders of a customer; only developers with a fulfillment role can check that.”)
Each has its pros and cons. In a good system, bad queries are stopped before they are executed. The GraphQL engine stops certain subqueries, and data requests received by the backends are further checked.
A good mechanism for the query structural–level check is to have each query come in with a JSON web token (JWT) token and for the GraphQL API endpoint to check for structural validity. So the above query presented along with a JWT token that has an entry: “enduser: john.doe@example.com” might be accepted, but the same query with a JWT token that contains “enduser: jane.smith@example.com” might be denied. More complex tokens and verification mechanisms might specify who could ask for orders or not.
Checking for rights in the backend often depends on the backends. Databases have good access-control mechanisms, so it is relatively straightforward to use the checks and balances there. REST backends are typically controlled by API keys, which are a coarser control. JWT and OAuth tokens are much better, but not all REST APIs implement them. And of course, the GraphQL layer must be able to pass the context down to the backend.
The checks and balances in the GraphQL layer pose their own challenges. Typically, a GraphQL implementation has a concept of “resolvers” — what code to execute when customer.orders needs to be populated. A key question is: what checks can be put on the resolvers? That is before customer.orders resolver can be called, is it even permitted to be called? Different implementations take different approaches to resolvers. In StepZen, they are query-based, connecting data in the enclosing object with a query in the enclosed object. So one might say, “Take the data customer.id and pass it as parameter customerId in the query getOrdersByCustomer and the data that is returned becomes the value of customer.orders.”
In this model, the query structural-level check serves as a resolver-based check — you kill two birds with one stone. In other ways of doing it, resolver-based checks have to be implemented separately.
Data Protection
HIPAA or PII (personally identifiable information) controls often prevent bits of data from being inadvertently leaked (Social Security numbers might get masked, names might get anonymized, etc.) However, in GraphQL, individual bits are important, but how they get combined is where the real danger lies.
Imagine a backend that produces the current employment details of a customer. And another backend that produces their demographics. What if the two, when combined, give a strong signal on the education level, and what if leaking the two bits of information together is the real problem, and individually each of them is harmless (assuming HIPAA and PII compliance). In this case, clearly, the GraphQL layer has to do some magic of masking or anonymizing etc. So a query
query MyQuery {
customerByEmail(email: "john.doe@example.com") {
name
age
employment {
company
position
}
}
}
is unacceptable, but a query without age or without position is acceptable? Implementing query structure-level controls requires too many combinations. A better approach is to add some bit of logic that says “mask age+position” allowing a much wider set of data to be queried for.
This kind of “individual bits are good, but together some might be bad” can only be implemented in the GraphQL layer. A common mechanism (which StepZen employs) is to enable “pre” and “post” logic around declarative query-based resolvers, and one use of such logic is to do the above masking.
Data Sovereignty
As we have discussed in a previous article, GraphQL has an in-built mechanism for federation (or a graph of graphs). So such an assembly is easily possible in GraphQL, whereas it is challenging to achieve in traditional REST implementations:
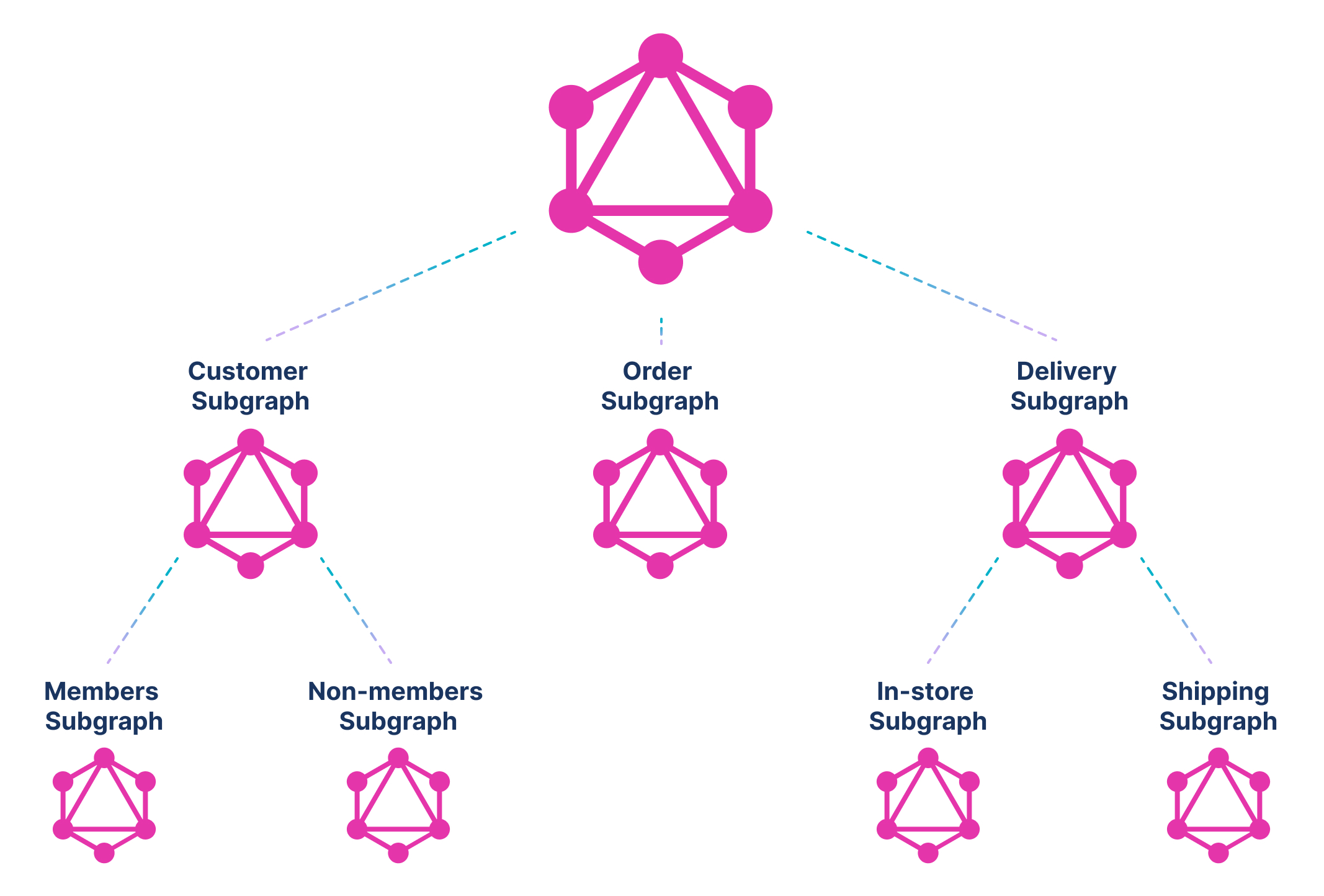
While we have done a functional decomposition above, it could as easily be a country- or continent-based decomposition (or any combination of geographic, cloud, functional, etc.). In the geographic decomposition, the customer subgraph might be built out of two subgraphs: a North America (NA) subgraph and a Europe (EU) subgraph.
Now each subgraph can implement its data sovereignty rules. For example, the EU subgraph can decide to only send aggregated information further up the chain, whereas the NA subgraph could send more details. Any level of data sovereignty can be built in once the concept — GraphQL is just a graph of graphs — is internalized.
Conclusion
As you saw, GraphQL makes data liquid. But that poses challenges in data rights, protection and sovereignty, to name just three. Each of these is not only solvable; sometimes it is much easier to do in GraphQL than in other approaches.
The time to march toward a future API architecture built on GraphQL is now. You can enable new business through these APIs, and yet you can relatively easily ensure that data vulnerabilities do not increase the cost of the new business.
Visit stepzen.com to read about StepZen's approach to helping developers build GraphQL to implement secure, performant data access. We'd love to share more and learn what you're working on - book a short call.
This article was originally published in The New Stack: 


