How GraphQL Helps on Your Journey to a Single Global Truth of Data

 Anant Jhingran
Anant JhingranAlmost all customers we work with have a data lake or data warehousing strategy--one place where analytical workloads can be executed, against a global truth of data. All the transactions that a customer does, across any channel, show up in the data lake. Good ETL (Extract, Transform, Load) pipelines ensure that this data is reasonably current.
And many of the customers we work with have a master data management (MDM) strategy--one system that keeps slower moving details — customers, products etc. — in a repository of global truth.
Why Data Lakes and MDM Systems are not the Whole Story
We also find that both the data lake and the master data systems are not the whole story when it comes to the complete global truth.
-
Data is being created faster than the right pipeline into the lake or MDM can be set up. So there is always an increasing amount of data that has either not made it to the global systems, or never will.
-
It takes time to model and map, and therefore many systems are in the product plans, but still a few quarters away.
-
Mergers and acquisitions often result in multiple systems with partitioned view of the data, even if each of the entities had their own data lake and MDM strategies.
-
Sometimes these systems become so complex that there is a consumption problem--how do you even find what you are looking for?
GraphQL Data Layer to the Rescue
GraphQL has been designed as a data layer for the ease of consumption across multiple backends. In GraphQL, one can ask for:
{
customer (email: "jane.smith@example.com") {
name
orders {
createdOn
products {
title
}
}
}
}
and the system assembles and returns customer, order, and product data. The developer requesting this information does not care for where the data is coming from — she just gets it!
The data itself might be coming from:
- A data lake for orders. All order transactions are available in the data lake.
- A master data system for customers.
- Two different product systems (maybe two different lines of products).
Composing the Graph in StepZen
StepZen is built on the concept of a "graph of subgraphs." Each backend exposes its capabilities as a "subgraph", and they get combined into a supergraph.
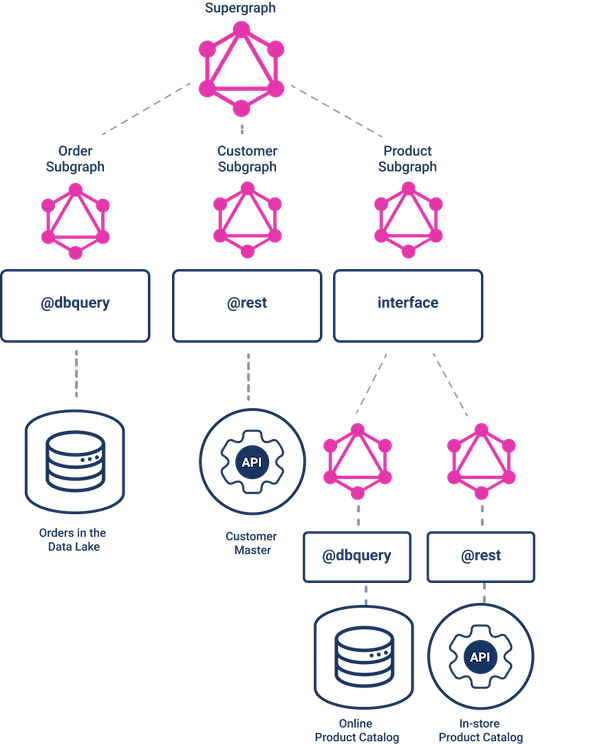
Each subgraph produces some GraphQL types (basically how the applications view the data, fully typed), and a set of queries and mutations (basically CRUD) on those types. This is pretty standard GraphQL.
In StepZen, this subgraph is annotated with some directives that tell StepZen how to populate that subgraph. A structure of a subgraph, say for order, might look like:
type Order {
createdOn: Date
customerId: ID
amount: Float
...
}
type Query {
orders(customerId: ID!): [Order]
@dbquery (type: "mssql", table: "data_lake_order", configuration: "mssql_config", ...)
}
The @dbquery directive tells StepZen that when a query orders(customerId: 23121) is to be executed, use a database connection pool from the configuration file mssql_config, and execute some command. (For information about using the @dbquery directive, see the StepZen Docs).
Let's now look into the structure of the entire graph.
The Order Subgraph
Your data lake or data warehouse might be in a database that supports a SQL interface like MSSQL, PostgreSQL, BigQuery, Db2, Teradata, etc. In that case, you can easily create the order subgraph using one of two techniques:
- Let StepZen introspect the database and generate a GraphQL schema for you. The StepZen CLI —specifically,
stepzen import name-of-database— does that for you. - You construct your subgraph by declaratively attaching SQL calls to your GraphQL schema. For example, you might use a directive
@dbqueryto build out your schema.
Or your data lake might be in a system that support REST APIs (e.g., a NoSQL system like MongoDB, or Hadoop's REST APIs), In that case, you can easily create the order subgraph using one of two techniques:
- Let StepZen introspect the data lake and generate a GraphQL schema for you. Use the StepZen CLI command —
stepzen import curl. - You construct your subgraph by declaratively attaching REST calls to your GraphQL schema. For example, you might use the GraphQL directive
@restto build out your schema. See Getting Started with a REST API in the docs.
The Customer Subgraph
Your customer master might be a homegrown service that supports a WSDL/SOAP interface. It is easy to generate the customer subgraph by transforming the returned XML of an HTTP SOAP request into JSON, using a parameter on an @rest call transforms with an editor xml2json. If your customer data comes from a database or a REST service, follow the instructions above.
The Product Subgraph
But what if there are two backends that produce product data? And furthermore, what if they produce it in different format? That is where the concept of interfaces comes in. We would declare:
interface Product {
title: String
price: Float
taxable: Boolean
}
type OnlineProduct implements Product {
...
}
type InStoreProduct implements Product {
...
}
...
See Design a Schema with Interfaces in the StepZen docs for information about assembling a schema that uses interfaces to access multiple backends.
Building the Supergraph
So how do these subgraphs get combined into one? How can the backend support a query like we gave in the beginning — one that fetches a customer detail, all the customer's orders, and the product details for those orders — all in one query?
This is where the power of "stitching" using declarative annotations comes in. The stitched graph looks something like this:
"""
The customer Subgraph
"""
"""
The order subgraph
"""
"""
The product subgraph
"""
extend type Customer {
orders: [Order]
@materializer (query: "orders")
}
extend type Order {
products: [Product]
@materializer (query: "getProductsByOrderId")
}
The extend clauses connect one subgraph with another. They take data from subgraph, feed it into a query/mutation of another subgraph, and take the returned data and make it a new field in the calling subgraph. See Linking Multiple GraphQL Types in docs for how to connect multiple GraphQL types using the @materializer directive. It is indeed that simple!
Summary
The volume and velocity of today's data mean that data lakes and MDMs are not the whole story when it comes to having a source of truth for analytical workloads and repositories for slower-changing data. A GraphQL data layer — a graph of graphs — can help as a business strives for a single global truth for all its data. In StepZen, each backend data source can expose its capabilities as a subgraph, and subgraphs are readily and declaratively assembled into a supergraph.
Signup for a free account and try it for yourself, and hit us up on Discord with questions and feedback.


