Tips for Creating a GraphQL Schema for an Existing Application

 Leonardo Losoviz
Leonardo LosovizWe have decided to start using GraphQL on an existing application. Great! Whether it is used for new or existing functionality, GraphQL will need to interact with the application's data layer, for which we need to map the application's data model into the GraphQL schema.
How should the mapping be done? Must it be done all at once? Should it be an exact replica of the existing data model? What about adjusting some inappropriate names in the process? And what about technical debt, should it be kept or dealt with?
In this article, I'll provide several tips for mapping an existing application's data model into a GraphQL schema, using WordPress as the example.
Map the schema at your own pace
Adding GraphQL to an application is not all or nothing. The same application could be powered by several APIs simultaneously, in which case GraphQL will live alongside other APIs for as long as needed. For instance, we could keep the existing functionality powered by REST, and incorporate GraphQL for all new functionality only.
If we want to do a complete migration to GraphQL, it doesn't have to happen all at once. The existing functionality could be slowly but steadily migrated to GraphQL, until one day GraphQL becomes the only API in the application.
Hence, even though we could create the complete GraphQL schema on day 1, we don't have to: At any given time, only those entities required by the functionality need to be present on the schema (via their types, fields, and interfaces). We can map them as time goes, in a progressive fashion.
Don't let the interface carry the burden of the implementation
The GraphQL server will implement the logic to access the application's data. It will do this by calling functionality from the underlying CMS (such as calling get_posts to retrieve post data in WordPress), or executing an SQL query against the DB or something else. At this layer, there will be implementation code.
A GraphQL schema, however, is an interface: It declares the contracts for accessing data in the API. It doesn't care about implementation details: It doesn't know anything about WordPress, or about the get_posts function , wp_posts database table or SQL queries.
As such, we should avoid leaking information between the layers, as much as possible.
This is important, because the data model will often be tarnished by its implementation. WordPress provides a clear example of this with the "attachment" custom post type (CPT) to represent media files such as images.
Because it is a CPT, an image is treated as a post. Then, we may be tempted to represent media files using the Post type, which contains these fields:
type Post {
id: ID!
title: String
content: String
excerpt: String
}
But this may not be appropriate for our application. The meaning of the "content" field is clear for a post, but it is not for an image. Most likely, it does not belong there.
An image was modeled as a CPT in WordPress because it was convenient, so it could reuse existing logic, and could be stored on the existing wp_posts table. However, convenient doesn't mean proper and may eventually lead to technical debt (i.e. defficient code which cannot be fixed without producing a breaking change, so it is kept in the application for longer than it should).
As much as possible, we don't want to keep technical debt in our application. Whenever given a chance, we should fix it. Mapping the data model to the GraphQL schema provides such an opportunity, allowing us to correct the problem at the data interface layer. (The technical debt will still persist at the application level though, so we're not fully fixing the problem, but instead limiting its impact.)
Let's put this idea into practice. Instead of having a Post type represent media files, it makes more sense to have a Media type, containing only those properties that do make sense for an image entity:
type Media {
id: ID!
src: String!
width: Int
height: Int
}
Under the hood, the GraphQL server may still execute function get_posts to resolve type Media, but that's of no concern to the GraphQL schema.
Decouple the GraphQL schema from the DB diagram
WordPress is implemented over this DB entity-relationship diagram:
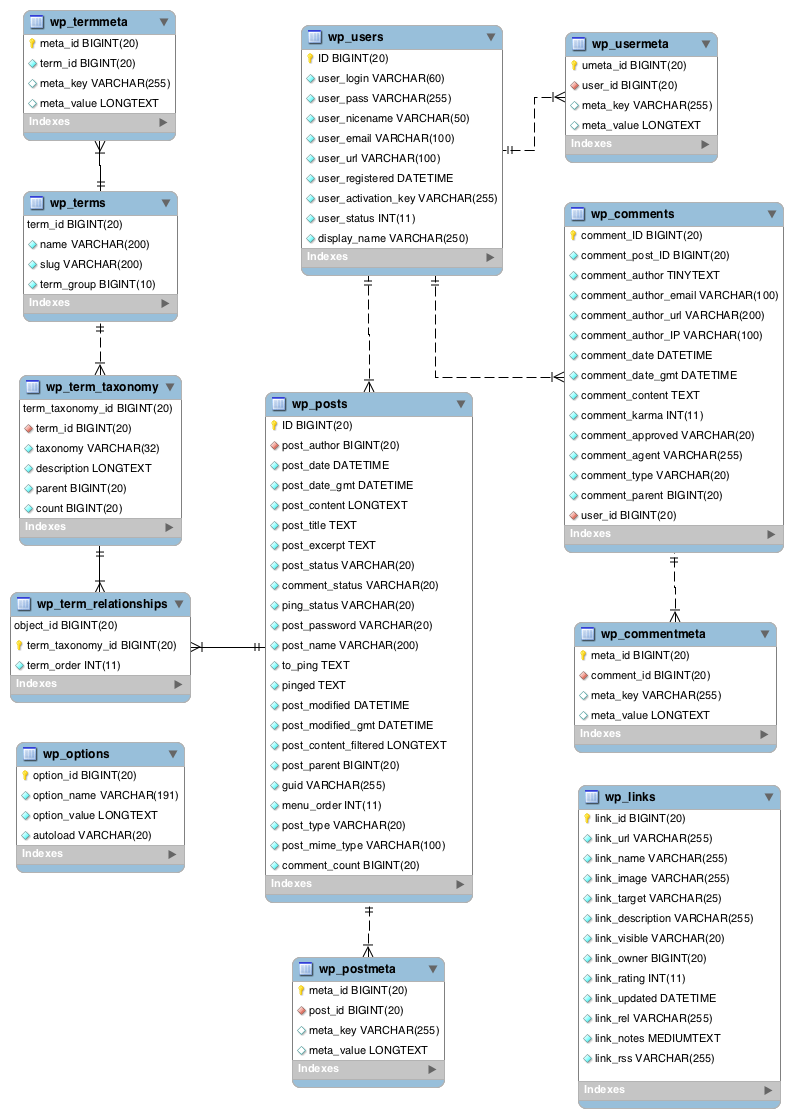
We must have the GraphQL schema be based on the DB diagram, but we should not attempt to create a 1 to 1 replica. That's because both the GraphQL schema and the DB diagram are built with certain preconditions or limitations, which will not apply to the other one.
The previous section demonstrates an example, where table wp_posts stores the data for the image CPT, but in GraphQL there will be two distinct types, Post and Media. Let's consider another example: categories. In WordPress, a post can have one or more categories, and any CPT can also create its own category. For instance, a CPT called "event" will have an "event_category".
Both post categories and event categories are stored in table wp_terms. This makes it easy for WordPress to fetch rows from one or the other category type, when executing the SQL query. Hence, we may be tempted to map categories via type Category, referenced by both posts and events:
type Category {
id: ID!
name: String!
}
type Post {
categories: [Category]!
}
type Event {
categories: [Category]!
}
However, a post will always contain post categories, and an event will always contain event categories. The data for these two category types may be stored on the same DB table, but it will not be mixed at the application level. Post category and event category are two distinct entities.
GraphQL has a static type system. To make the most of GraphQL, different entities at the application level must be modeled using different types in the GraphQL schema.
In this case, when mapping categories into the GraphQL schema, we should create a different type for each of them: PostCategory and EventCategory. Then, type Post will only reference PostCategory, and type Event will only reference EventCategory:
type PostCategory {
id: ID!
name: String!
}
type Post {
categories: [PostCategory]!
}
type EventCategory {
id: ID!
name: String!
}
type Event {
categories: [EventCategory]!
}
If we still want to have an entity in the schema that comprises all categories, this can be achieved via an interface Category:
interface Category {
name: String!
}
type PostCategory implements Category {
id: ID!
name: String!
}
type EventCategory implements Category {
id: ID!
name: String!
}
This way, the users accessing the API will have a clear understanding of what data will be retrieved, independently of how it's mapped in the DB diagram, and how it's stored in the DB.
Once we have the final GraphQL schema, we can appreciate that its shape will somewhat resemble the WordPress DB diagram, yet be clearly different from it:
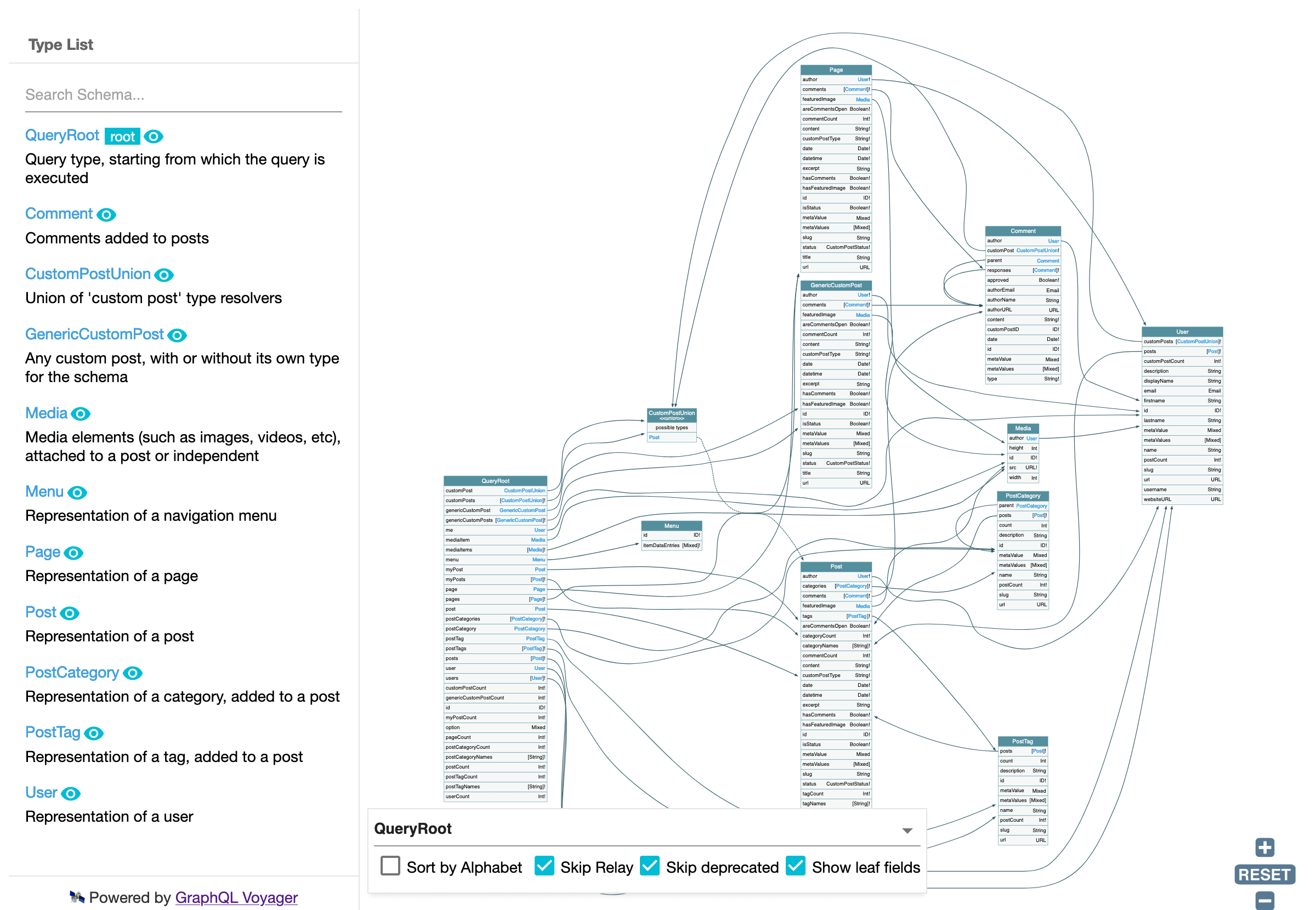
Adapt the naming of fields to the static typing
Fields should, as much as possible, respect the same naming they have on the application.
For instance, in Wordpress we can create a post with the function wp_insert_post, and the post has properties "title" and "content". These names are also good for the GraphQL schema (even though they may need slight modifications), so we should keep them:
type MutationRoot {
insertPost(title: String, content: String): Post
}
type Post {
id: ID!
title: String
content: String
}
But that's not necessarily the case all the time. As we saw earlier on, custom posts must be decoupled into their own entities. Then, while function get_posts retrieves a list of any CPT, an equivalent field posts in the root type of the schema will only retrieve entities of type Post but not Page (which is also a CPT):
type QueryRoot {
posts: [Post]!
}
Then, how do we obtain the list of all posts and pages? Via yet another field, customPosts, which retrieves the entities of any CPT mapped under union type CustomPostUnion:
union CustomPostUnion = Post | Page
type QueryRoot {
customPosts: [CustomPostUnion]!
}
The important lesson is this one: The naming we choose for the GraphQL schema must be adapted to the type of the retrieved entity. And due to GraphQL's strong types, such a type may be different at the application and API layers.
In this case, while in WordPress a "post" could mean any "custom post type", in GraphQL a "post" is necessarily a Post. If a field retrieves custom posts, then the field in the GraphQL schema must be named customPosts, not posts. Similarly, if an input receives an ID for a custom post, it must be called customPostID, not postID.
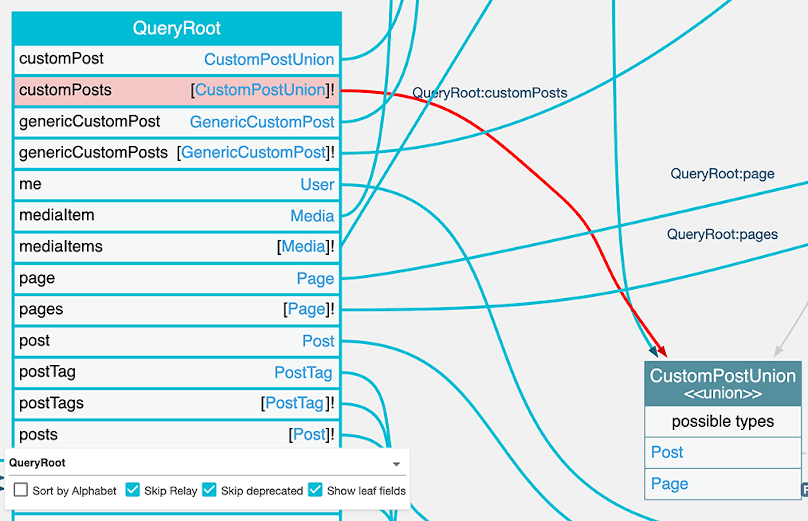
This lesson is applied to comments, for instance. A comment can be added to any CPT, not just to posts. Then, the Comment type must make this clear, by containing field customPost (and not post):
type Comment {
id: ID!
customPost: CustomPostUnion!
}
Convert predefined string values to enums, using uppercase if possible
Enumeration types are, by convention, defined in uppercase. For instance, the documentation from graphql.org provides this example:
enum Episode {
NEWHOPE
EMPIRE
JEDI
}
Whenever we have to create a new enum type, we should use uppercase for its defined constants. However, when migrating the data model from the application, we may encounter certain sets of predefined values that we can map via an enum, but whose values are lowercase strings.
To provide an example, posts in WordPress has a "status" property that can contain one of the following values:
"publish""pending""draft""trash"
When mapping this property on the schema, the Post.status field could return a String, like this:
type Post {
status: String!
}
However, since the status will necessarily be one of those predefined values, and none other, we'd rather map it as an enum:
enum Status {
PUBLISH
DRAFT
PENDING
TRASH
}
type Post {
status: Status!
}
Now, we may have a problem: The enum PUBLISH will be converted to the string value "PUBLISH" in the application, and not "publish" (that is, unless the GraphQL server implements some mechanism to convert between them). Using an uppercase value, instead of the expected lowercase one, the logic in the application may be disrupted. Indeed, executing the following code in WordPress does not work:
// This will retrieve all posts, not only the published ones
$published_posts = get_posts([
"post_status" => "PUBLISH",
]);
In this case, we should consider trading convention with convenience, still using an enum to map the constants, but in lowercase:
enum Status {
publish
draft
pending
trash
}
In other words, we can have a middle ground between being proper, and being practical. We should use best practices when building the GraphQL schema, but allow ourselves to deviate from them whenever it makes sense.
Conclusion
I have had the experience of migrating the WordPress data model into a GraphQL schema, and I described the lessons I learned while doing so. WordPress is a good example since, being 18 years old, it has accumulated its fair share of technical debt, and its naming conventions and involved entities (such as posts, custom posts, and comments) are widely known.
Mapping the data model from an existing application into a GraphQL schema demonstrates one of the benefits of GraphQL: It can "rejuvenate" the application. Whenever the application suffers from issues (whether it has avoided using types, been affected by improper naming, or something else), the GraphQL schema can help breath new life into it, by fixing some of these issues.
As old as our applications may be, it's never too late to add GraphQL to them.


